
We begin with an inequality for probability density functions, sometimes referred to as the information inequality. We use this inequality to prove that the Kullback-Leibler divergence, a `distance’ between two probability measures, is always nonnegative.
Proposition 1.
for all nonnegative functions measurable functions
satisfying
.

Proof. Let 

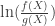
![\displaystyle\mathbb{E}\left[\ln\left(\frac{f(X)}{g(X)}\right)\right]=\int_{-\infty}^{\infty}f(x)\ln\left(\frac{f(x)}{g(x)}\right)dx\geq 0](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%5Cmathbb%7BE%7D%5Cleft%5B%5Cln%5Cleft%28%5Cfrac%7Bf%28X%29%7D%7Bg%28X%29%7D%5Cright%29%5Cright%5D%3D%5Cint_%7B-%5Cinfty%7D%5E%7B%5Cinfty%7Df%28x%29%5Cln%5Cleft%28%5Cfrac%7Bf%28x%29%7D%7Bg%28x%29%7D%5Cright%29dx%5Cgeq+0&bg=ffffff&fg=333333&s=0&c=20201002)
Since 
![\begin{array}{lcl}\displaystyle\mathbb{E}\left[\ln\left(\frac{g(X)}{f(X)}\right)\right]\leq\ln\mathbb{E}\left[\frac{g(X)}{f(X)}\right]=\ln\left(\int_{-\infty}^{\infty}\frac{g(x)}{f(x)}f(x)dx\right)&=&\ln\left(\int_{-\infty}^{\infty}g(x)dx\right)\\&=&\ln 1\\&=&0\end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Blcl%7D%5Cdisplaystyle%5Cmathbb%7BE%7D%5Cleft%5B%5Cln%5Cleft%28%5Cfrac%7Bg%28X%29%7D%7Bf%28X%29%7D%5Cright%29%5Cright%5D%5Cleq%5Cln%5Cmathbb%7BE%7D%5Cleft%5B%5Cfrac%7Bg%28X%29%7D%7Bf%28X%29%7D%5Cright%5D%3D%5Cln%5Cleft%28%5Cint_%7B-%5Cinfty%7D%5E%7B%5Cinfty%7D%5Cfrac%7Bg%28x%29%7D%7Bf%28x%29%7Df%28x%29dx%5Cright%29%26%3D%26%5Cln%5Cleft%28%5Cint_%7B-%5Cinfty%7D%5E%7B%5Cinfty%7Dg%28x%29dx%5Cright%29%5C%5C%26%3D%26%5Cln+1%5C%5C%26%3D%260%5Cend%7Barray%7D&bg=ffffff&fg=333333&s=0&c=20201002)
Observing that ![\mathbb{E}[\ln(\frac{g(X)}{f(X)})]=-\mathbb{E}[\ln(\frac{f(X)}{g(X)})]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Cln%28%5Cfrac%7Bg%28X%29%7D%7Bf%28X%29%7D%29%5D%3D-%5Cmathbb%7BE%7D%5B%5Cln%28%5Cfrac%7Bf%28X%29%7D%7Bg%28X%29%7D%29%5D&bg=ffffff&fg=333333&s=0&c=20201002)

The information inequality is used to showed that the Kullback-Leibler divergence between two distributions 



is nonnegative. Note that the Kullback-Leibler divergence can be generalized to the case where 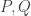
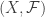



where 
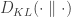
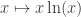

Note that, although the KL-divergence can be intuivitely thought of as a `distance’ between two probability measures, it does not define a metric since it need not be symmetric. For a simple counter example, let 

![\displaystyle D_{KL}(P \parallel Q)=\frac{1}{2}\left[\ln\left(\frac{3}{2}\right)+\ln\left(\frac{3}{4}\right)\right]\approx . 059,](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+D_%7BKL%7D%28P+%5Cparallel+Q%29%3D%5Cfrac%7B1%7D%7B2%7D%5Cleft%5B%5Cln%5Cleft%28%5Cfrac%7B3%7D%7B2%7D%5Cright%29%2B%5Cln%5Cleft%28%5Cfrac%7B3%7D%7B4%7D%5Cright%29%5Cright%5D%5Capprox+.+059%2C&bg=ffffff&fg=333333&s=0&c=20201002)
while
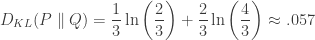
We now apply the information inequality to proving some results concerning maximal entropy. Define the entropy of
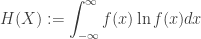
We also use the notation 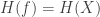
We now prove that the 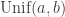

![g(x):=(b-a)^{-1}\mathbf{1}_{[a,b]}(x)](https://s0.wp.com/latex.php?latex=g%28x%29%3A%3D%28b-a%29%5E%7B-1%7D%5Cmathbf%7B1%7D_%7B%5Ba%2Cb%5D%7D%28x%29&bg=ffffff&fg=333333&s=0&c=20201002)
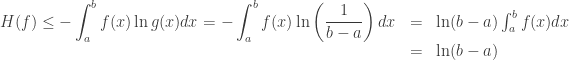
Taking 
We now prove that 



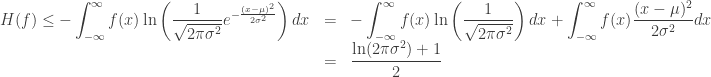
since if
![\displaystyle\sigma^{2}=\text{Var}(X)=\mathbb{E}[(X-\mathbb{E}[X])^{2}]=\mathbb{E}[(X-\mu)^{2}]=\int_{-\infty}^{\infty}f(x)(x-\mu)^{2}dx](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%5Csigma%5E%7B2%7D%3D%5Ctext%7BVar%7D%28X%29%3D%5Cmathbb%7BE%7D%5B%28X-%5Cmathbb%7BE%7D%5BX%5D%29%5E%7B2%7D%5D%3D%5Cmathbb%7BE%7D%5B%28X-%5Cmu%29%5E%7B2%7D%5D%3D%5Cint_%7B-%5Cinfty%7D%5E%7B%5Cinfty%7Df%28x%29%28x-%5Cmu%29%5E%7B2%7Ddx&bg=ffffff&fg=333333&s=0&c=20201002)
Taking 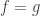

It is in reality a nice and helpful piece of info. I am happy that you simply shared this helpful info with us. Please stay us informed like this. Thank you for sharing.
You’re using Jensen’s inequality the wrong way around! You’ll need to rethink your first proof…
Thank you for your comment. I take it that you are referring to the proof of Proposition 1. I reviewed my proof, and I’m not seeing the mistake. f(x) = ln(x) is a concave function (compute the second derivative), so Jensen’s inequality is reversed.
I think there is a subtle problem with the first proof: g(x)/f(x) * f(x) = g(x) only on the set {f(x) != 0}, which is not necessarily dx-measure zero (although it is measure zero with respect to the probability measure corresponding to f(x)). On the set {f(x) = 0}, we have instead g(x)/f(x) * f(x) = 0. As such,
int g(x)/f(x) * f(x) dx = int_{f(x) != 0} g(x) dx
which in general is only equal to
int g(x) dx
when {f(x) != 0} is dx-measure zero.
However, I agree with your proof of the more general case, which can easily be specialised to this case here.